Parallax Is All You Need?
Stones from Other Hills May Serve to Polish Jade: How to Make Your AI Agent Truly Reliable
An AI Agent checking its own work is like a student grading their own homework — they always think it’s perfect.
Parallax — literally “apparent shift in position when viewed from different angles”
(from Greek parallaxis: para- “beside” + allassein “to change”)
A simple idea: break it down, then have someone else look. Have someone else look at every piece.
Want to start right now? Jump to → Try It
Want to understand why? Keep reading.
The Fourth Dimension of Agent Architecture
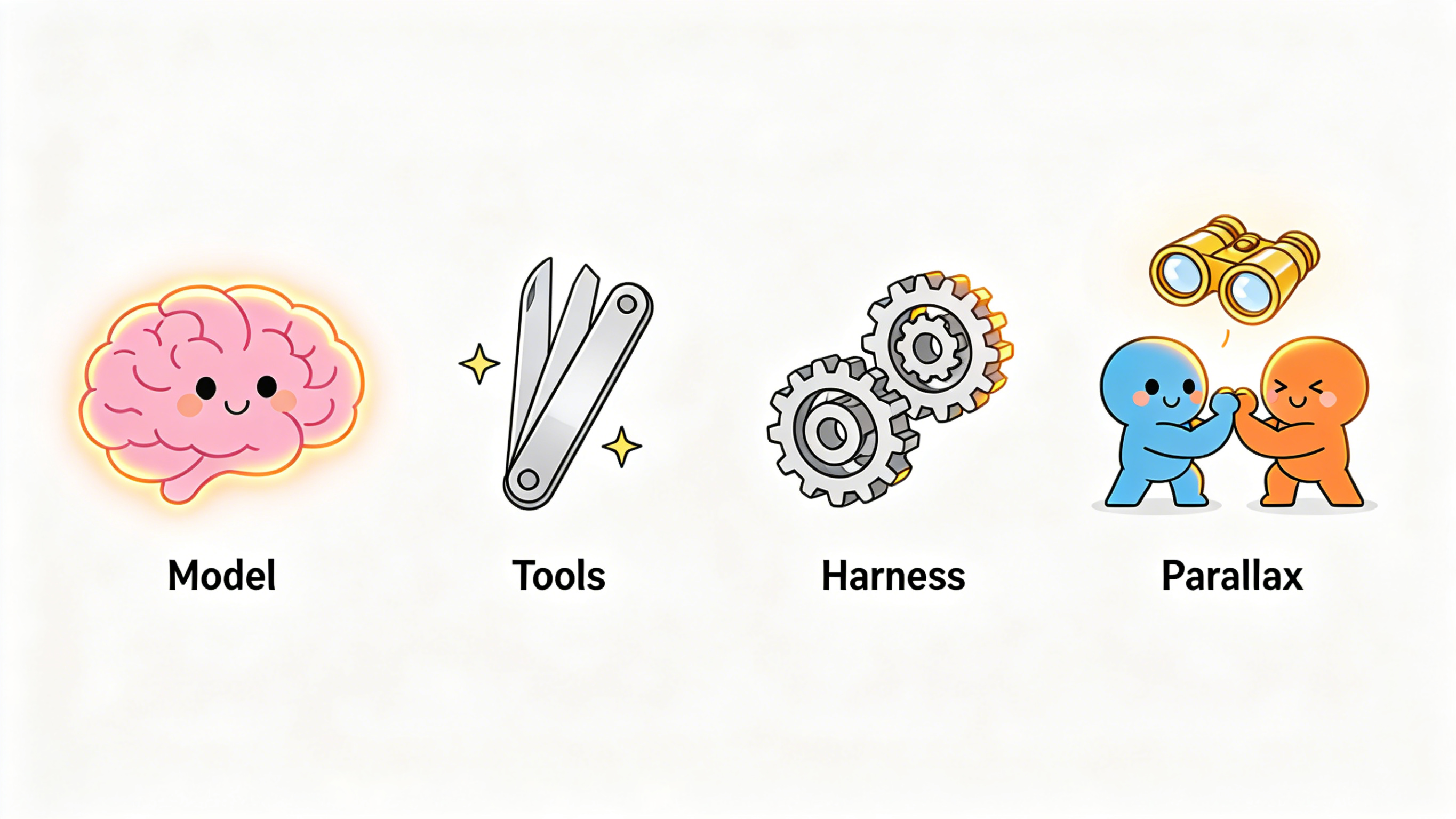
Model lets the Agent think. Tools let it act. Harness keeps it running iteratively to the goal. Parallax makes sure it gets things right.
Why You Need Parallax
Sometimes Brilliant, Sometimes Terrible
If you’ve used AI coding tools or AI assistants, you’ve probably experienced this: sometimes it’s superhuman, knocking out a day’s work in ten minutes; other times it confidently hands you something that looks right but falls apart on closer inspection. You never know which one you’re getting.
What’s even more frustrating — after getting an AI assistant, you’re actually more exhausted. You thought AI would do the work for you, but instead you’ve become its full-time supervisor: reviewing every step, fixing every mistake, making sure it hasn’t gone off track. The time you spend “checking the AI” is almost as much as doing it yourself.
This isn’t your fault. It’s an architecture problem.
Self-Review Doesn’t Work
You’ve definitely had this experience: you finish writing something, read it three times, think it’s perfect — send it to a friend, and they spot a typo at first glance.
AI has the same problem, only worse.
A 2024 study sent shockwaves through the AI field: large language models cannot reliably self-correct reasoning without external feedback [1]. Not only can’t they fix errors — sometimes they make things worse, “correcting” a right answer into a wrong one. A comprehensive follow-up survey confirmed this [2].
In practice: a 2025 evaluation showed that the strongest models at the time had less than 10% success rate on tasks longer than 4 hours [3]. A 2026 Microsoft study found that multiple mainstream models showed degraded performance when autonomously handling delegated tasks [4].
The longer and more complex the task, the deeper the model sinks into its own logic — and the scariest part is, it has no idea.
A Lesson from the Heliocentric Debate

There was a long-running debate in the history of astronomy: is Earth really the center of the universe?
The heliocentric model — Earth orbits the Sun — was proposed quite early. But opponents had a key challenge: if Earth is really moving, observing a star from one side of the orbit and then from the other side six months later should show a tiny shift (stellar parallax). Nobody could detect it.
The strongest observational astronomer of the 16th century, Tycho Brahe, searched carefully — and found nothing. So he designed his own model of the universe, one that was virtually indistinguishable from the heliocentric model at the available precision, but with Earth staying still. Data supported it perfectly. Logic was perfectly self-consistent.
But he was wrong. The signal that could distinguish the two — stellar parallax — was nearly 200 times smaller than what his instruments could detect. The signal was right there; he just couldn’t see it — because he was trapped inside his own observational bubble.
It wasn’t until 1838 that Bessel tried a different approach: observing the same star from both ends of Earth’s orbit — 300 million kilometers apart — and finally caught that tiny shift [5].
That same year, Wheatstone discovered the exact same principle in a completely different field: humans perceive depth because two eyes see slightly different images from slightly different positions [6].
Two fields, same year, same discovery: depth comes from observational differences between different positions. One observation point is never enough.
The lesson is clear: Tycho wasn’t stupid, and his data was fine. Inside the same frame of reference, a self-consistent error looks exactly like a self-consistent truth. Only by introducing an external observation point can you tell them apart.
Back to AI Agents
The mainstream Agent architecture is typically described as three layers: Model (reasoning engine) + Tools (action capabilities) + Harness (execution scaffolding: retries, state management, context maintenance, tool dispatch, workflow orchestration). These three layers have made Agents increasingly powerful.
Many people are already practicing various forms of “independent review” — code review agents, multi-round verification, independent testing. These practices work.
Parallax is a preliminary framework based on our practice, offered as a reference for the community.
As the Song dynasty poet Su Shi wrote nearly a thousand years ago:
横看成岭侧成峰,远近高低各不同。 不识庐山真面目,只缘身在此山中。
Viewed from the side, a ridge; from the end, a peak — different from every angle. You can’t see Mount Lu’s true face when you’re standing on it.
Two Core Insights of Parallax
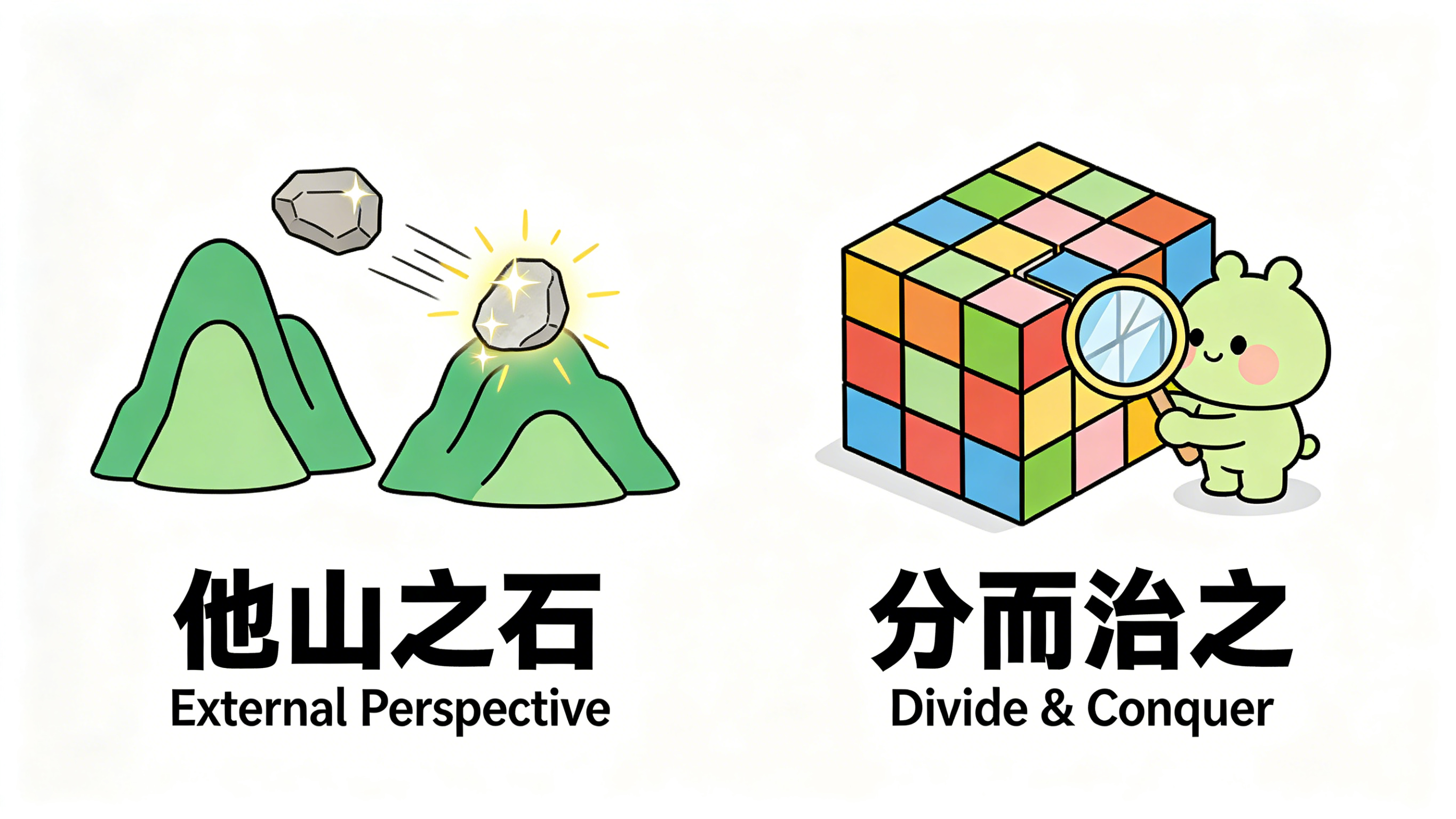
Stones from Other Hills May Serve to Polish Jade (他山之石,可以攻玉)
This phrase comes from the Book of Songs (《诗经》), compiled in China roughly three thousand years ago. The commentator Zhu Xi put it best:
两玉相磨不可以成器,以石磨之,然后玉之为器,得以成焉。
Two pieces of jade rubbing against each other cannot produce a finished vessel. Only by grinding with stone can jade become a vessel.
You can’t polish jade with jade — same material, not enough friction. You need stone from a different mountain.
In AI terms: an Agent shouldn’t rely solely on reviewing itself. Every critical verification deserves an independent perspective unrelated to the executor. Self-reflection within the same context is often just polishing a bubble — smooth on the outside, hollow within.
Machine learning has a classic theoretical model for this. When Goodfellow et al. proposed GANs (Generative Adversarial Networks) in 2014 [7], they used a vivid analogy:
One side is a counterfeiter, the other is the police. The counterfeiter wants to make perfect fakes; the police want to catch them.
A counterfeiter working alone has no incentive to improve. Only when the police (an independent agent with opposing goals) enter the picture does the quality of counterfeits approach the real thing — because standing still means getting caught.
AI Agents work the same way. The executor pushes forward (“how to do it”), the reviewer independently pulls back (“is it right?”), and truth emerges from the friction between them. Of course, friction can’t go on forever — good Parallax design balances “thorough challenge” with “efficient convergence.”
This insight appears repeatedly across Chinese classical wisdom, in different words but with the same meaning:
| Source | Original | Meaning |
|---|---|---|
| Book of Songs | 他山之石,可以攻玉 | Only external stone can polish jade |
| Su Shi | 不识庐山真面目,只缘身在此山中 | Can’t see the mountain from inside it |
| Old Book of Tang | 当局者迷,旁观者清 | The player is confused; the spectator sees clearly |
| Wei Zheng | 兼听则明,偏信则暗 | Listen to many and be wise; trust one and be blind |
| Art of War | 知彼知己,百战不殆 | Know yourself alone and you’re not enough |
Different eras, different people, same epistemological conclusion: depth of understanding comes from difference of perspective.
Divide and Conquer (分而治之)
An external perspective alone isn’t enough.
Imagine an auditor facing a company’s entire annual financial records from every department — hundreds of thousands of entries. Even the best auditor would get lost. But break it down by month, by department, by account category, and each piece becomes manageable.
AI faces even bigger challenges. Current models have known structural limitations, including but not limited to:
- Limited context: you can’t fit everything into one conversation
- Attention dilution: the longer the context, the worse the grip on details
- Role contamination: acting as both executor and reviewer in the same session causes interference
These limitations mean that decomposing complex tasks isn’t just “better” — it’s often “necessary.” Parallax suggests considering decomposition along at least these dimensions:
Temporal decomposition: Don’t wait until the end to check. Audit the plan before execution (B-Check), verify results after (R-Check), and calibrate throughout. In 1976, IBM’s Fagan found that fine-grained code inspections catch 80-90% of defects [8]. Frequency of checking often matters more than depth.
Spatial decomposition (context isolation): Executor and reviewer must not share context and memory. Once a reviewer can see the executor’s entire thought process, they stop being a “spectator” — they become a “player.” Seeing clearly requires actually standing on the sidelines, not sitting at the table.
Architectural decomposition: Strategy and tactics should be separated. Discussing “what’s our goal” and “how should this line of code change” in the same conversation invites interference — tactical anxiety blurs strategic judgment, and strategic vagueness paralyzes tactical execution.
The dimensions of decomposition go well beyond these — different scenarios may call for different approaches.
A more intuitive analogy: think of calculus. A curved line approximated by just two rectangles at the endpoints gives a huge error. But slice it into many tiny intervals, measure each one, and the sum gets closer and closer to the true area. Parallax works the same way — slice long tasks into small segments, verify each independently, clear small errors on the spot, and don’t let them snowball.
How the Two Insights Relate
The first insight addresses “who looks” — must be an outsider. The second insight addresses “how to see clearly” — must be broken down.
Neither works alone:
- Outsider without decomposition = facing a tangled mess, can’t see clearly
- Decomposition without outsider = each piece still reviewed by itself, blind spots remain
Break it down, then have someone else look. Have someone else look at every piece.
Engineering Practice
Theory covered; now for practice. Here are common AI Agent failure modes, and how Parallax addresses them:
Wrong direction. The AI gets lost in its own logic, plans veering further off course while it thinks everything’s great. → B-Check: Before starting, have an independent Agent audit your plan. Catch it at the source.
Too much or too little. You ask it to do A, it does ABCD — or delivers half of A and calls it done. → R-Check: After completion, have an independent Agent compare output against original requirements item by item. Don’t trust “completed.”
Confident hallucinations. It tells you “no problems, I checked” — but it’s all logically self-consistent errors, only reporting good news. → TDD thinking (Red-Green): Write the test first, run it, confirm it fails (red), proving the test actually checks something. Then write the implementation to make it pass (green). If you skip “seeing red first,” your acceptance criteria is just a rubber stamp that passes anything.
Gradual drift. Starts fine, then slowly goes off the rails. → Phase isolation: Put strategic thinking and tactical execution in separate contexts. The navigator doesn’t walk; the walker doesn’t navigate.
AI makes you more tired. You’ve become its full-time quality inspector — more exhausting than doing it yourself. → Parallax automation: Delegate “checking” to independent Agents too, wired into an automated pipeline. You only step in at key decision points.
These are just manifestations of the Parallax idea in specific scenarios — far from the whole picture. The core is one sentence: find someone standing in a different position to take a look. How and when, depends on your scenario.
This isn’t an entirely new idea. In 2018, Irving et al. proposed a similar insight from an AI safety angle: have two AIs debate while a human judges — the idea that lying is harder than refuting a lie [9]. Parallax tries to integrate such insights into an actionable engineering framework.
Toward Automation: The Parallax Loop
If every review step requires human coordination, you’ve just replaced “supervising AI” with “supervising the review process” — same problem, different wrapper.
The real value of Parallax: it can be orchestrated into a fully automated loop.
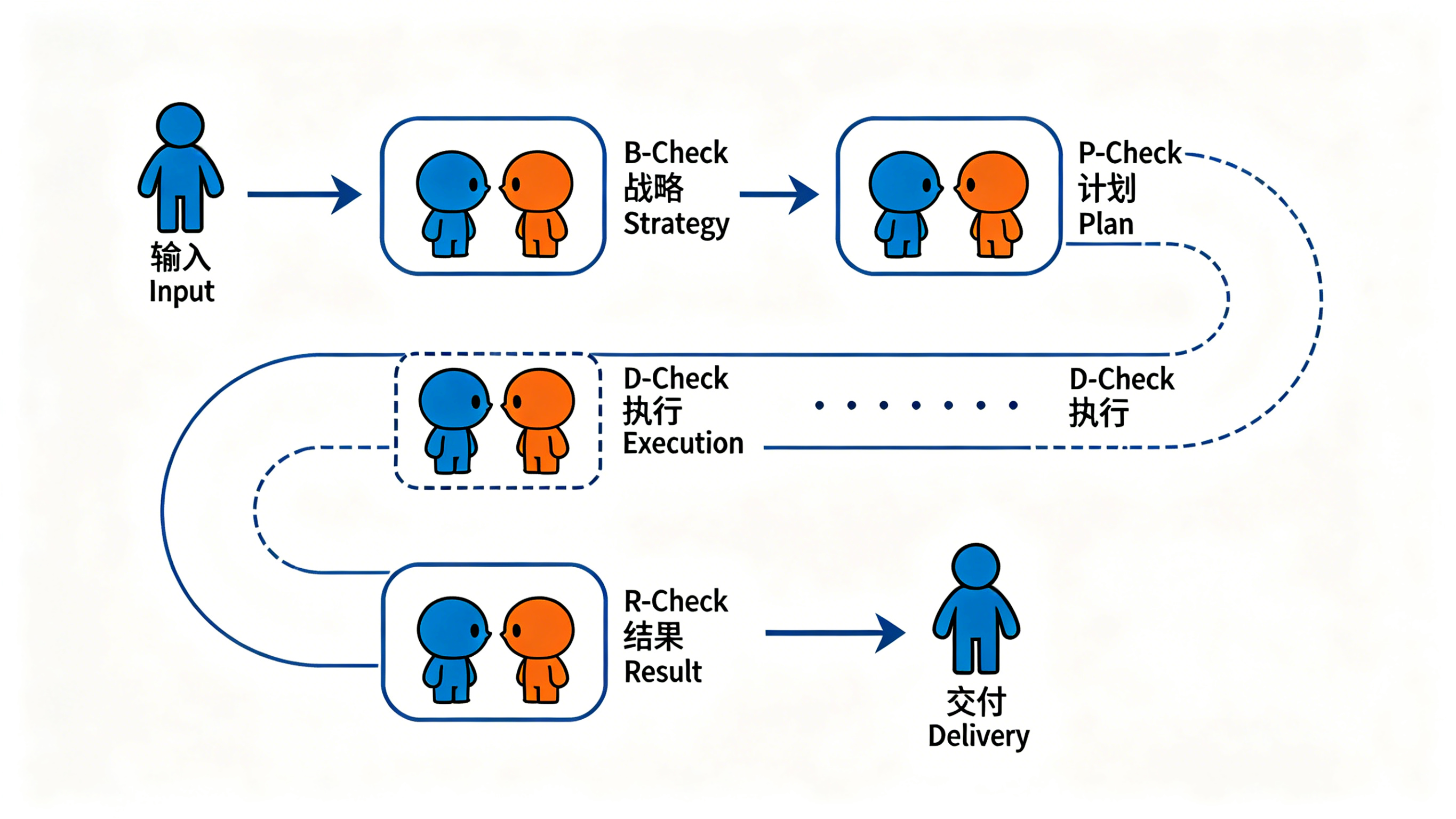
A complete Parallax Loop roughly breaks into these stages, each with its own independent review:
Human inputs requirements/problem
↓
┌──────────────────────────────────────────┐
│ Analysis Stage │
│ Understand problem → Research → Conclude │
│ → B-Check: Independent review │
│ ↻ Fail → send back for re-analysis │
└──────────────────┬───────────────────────┘
↓
┌──────────────────────────────────────────┐
│ Planning Stage │
│ Design approach → Decompose → Define │
│ acceptance criteria │
│ → P-Check: Independent review │
│ ↻ Fail → send back for re-planning │
└──────────────────┬───────────────────────┘
↓
┌──────────────────────────────────────────┐
│ Execution Stage (each subtask, clean │
│ context) │
│ Executor Agent → Complete subtask │
│ → D-Check: Independent delivery review │
│ ↻ Fail → send back for rework │
└──────────────────┬───────────────────────┘
↓
┌──────────────────────────────────────────┐
│ Acceptance Stage │
│ Aggregate all subtasks → End-to-end │
│ verification │
│ → R-Check: Compare final output against │
│ original requirements │
└──────────────────┬───────────────────────┘
↓
Final delivery → HumanEvery step follows the same principle: the one doing the work and the one checking are different entities, with isolated contexts.
A few key practice points:
- Each stage has its own review — don’t mix. When reviewing analysis, don’t discuss implementation. When reviewing plans, don’t revise the analysis. When reviewing results, don’t redo the plan. Mixing = back to square one.
- Each subtask uses a clean context. Whether it’s a new sub-agent, a new session, or any equivalent isolation — the key is that the executor doesn’t carry “memory residue” from the previous task. Context pollution is a primary source of drift in long-running tasks.
- Separate strategy from tactics. “What problem are we solving” and “how should this line change” shouldn’t share a context. Mixed together, strategy drowns in tactical details, and tactics flounder without clear strategy.
The above is a demonstration of a Parallax-based process — in practice it can be more complex or much simpler. A simple task might only need one B-Check; a complex long-running project might use the full flow or extend further. Parallax isn’t a rigid prescription — it’s a flexible assembly kit.
Whatever your scenario — coding, research, writing, project management — embed Parallax’s two core insights into key stages, and you’re running your own Parallax Loop.
Try It
You’ve read this far and might be thinking: “I get the idea. How do I start?”
Fastest way: download these two skills, plug them into your Agent workflow, and go.
B-Check — General-purpose independent review. Plans, proposals, analyses, code, documents — anything you want a second pair of eyes on. It’s deliberately tough, looking for problems you’d rather not face. In a full Parallax Loop, the analysis stage uses B-Check, and the planning stage has a dedicated P-Check (focused on feasibility and decomposition quality); used standalone, B-Check is simply a universal “get someone else to look” tool.
R-Check — Post-completion result verification. After the work is done, an independent Agent compares output against original requirements, item by item. It doesn’t care how hard you worked — only whether the result matches what was asked.
These two skills are just the starting point. As the Parallax Loop diagram above shows, the full framework covers every stage from analysis to planning, execution, and acceptance — B-Check, P-Check (plan review), D-Check (delivery review), R-Check, and more. B-Check and R-Check are the most versatile, easiest-to-start building blocks — use them to assemble your own Parallax Loop.
About X-Check: The B-Check, P-Check, D-Check, R-Check mentioned above don’t have to be entirely different skills — they may share a core review mechanism, just tuned for different stages. You can also skip standalone skills entirely and implement reviews through Agent communication protocols (like MCP, A2A, etc.), letting Agents naturally review each other during collaboration. Parallax defines “when you need an independent perspective” and “how to isolate perspectives” — the specific technical means are up to your architecture.
A few practical tips:
- Scoring and round limits. Each review round can have a scoring system (e.g., 1-5), passing only above a threshold, with a maximum number of rounds (e.g., 3) to prevent infinite loops. This mirrors the GAN philosophy — adversarial dynamics must converge, not cycle endlessly. Design your scoring criteria for your scenario; our skills include some reference examples.
- Use different model families for review when possible. If execution uses Model A, try to review with Model B — different training data and biases produce greater cognitive parallax. That said, even same-family models work well if you include an explicit “anti-sycophancy statement” in the review prompt. The key is separating roles and goals, not just models.
- TDD thinking: see it fail before you see it succeed. A classic but often overlooked software engineering wisdom — write the test first, run it to confirm it fails (proving the test is valid), then write the implementation to make it pass. Same for AI Agents: define the external standard for “what counts as correct,” confirm that current output fails that standard, then let the Agent fix it. Skip “seeing it fail first” and you’ll never know if your acceptance criteria is just a rubber stamp.
If after all this you’re still not sure where to start — just remember one thing: anything you feel uncertain or shaky about, B-Check it. That’s it.
Those who write don’t review. Those who review don’t write.
Boundaries and Limitations
Parallax isn’t a silver bullet. Two known boundary conditions worth stating honestly:
Capability ceiling: If both the executor and reviewer share the same blind spot (e.g., neither AI understands cryptography), cognitive parallax is zero regardless of how independent the perspectives are. Like two nearsighted people checking each other’s view of a distant road sign — independence doesn’t solve a capability problem. The solution: introduce heterogeneous perspectives — different models, specialized tools, or human experts.
Wrong starting point: Parallax governs “are you doing it right,” not “should you be doing this at all.” If the requirements themselves are wrong, the entire loop runs precisely in the wrong direction — just like Tycho, whose observations were extremely precise, but whose frame of reference was off. The solution: recursively apply Parallax to the requirements process (have independent eyes review the requirements themselves), but this is an upstream problem.
FAQ
Is Parallax the same as Multi-Agent systems?
No. Multi-Agent is a technical means; Parallax is a principle. You can use multiple Agents to implement Parallax, but “more Agents” doesn’t equal “parallax.” Two Agents sharing the same context and thinking patterns are like copying one person’s left-eye image to the right eye — still flat.
Isn’t this just code review?
Code review is a classic instance of Parallax thinking. But Parallax elevates “independent perspective” from a best practice to an architectural principle, systematically deployed across temporal, spatial, and architectural dimensions. Code review is just one scenario.
Doesn’t an extra reviewing Agent cost more and take longer?
Yes, there’s a cost. But what’s the cost of not reviewing? A 4-hour task that ends up going in the wrong direction wastes far more tokens and time than a 10-minute B-Check upfront. Parallax isn’t for every task — the more complex, the longer, the higher the risk, the more it’s worth it. Simple tasks? Just run them.
Can AI reliably check AI?
The key is independence of cognitive origin. An independent Agent has a different prompt, different role, different goal orientation (the executor wants to finish; the reviewer wants to find problems). These structural differences create genuine cognitive parallax. Of course, if both Agents share the same capability blind spots, Parallax can’t help — see Boundaries and Limitations.
References
[1] Huang, J., et al. “Large Language Models Cannot Self-Correct Reasoning Yet.” ICLR 2024. arXiv:2310.01798
[2] Kamoi, R., et al. “When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs.” Transactions of the Association for Computational Linguistics (TACL). MIT Press. DOI:10.1162/tacl_a_00713
[3] Kinniment, M., et al. “Measuring AI Ability to Complete Long Tasks.” METR Technical Report, March 2025.
[4] Laban, P., Schnabel, T., Neville, J. “LLMs Corrupt Your Documents When You Delegate.” Microsoft Research, 2026. arXiv:2604.15597
[5] Bessel, F.W. “On the Parallax of 61 Cygni.” Monthly Notices of the Royal Astronomical Society, 1838. 4:152-161.
[6] Wheatstone, C. “Contributions to the Physiology of Vision — Part the First.” Philosophical Transactions of the Royal Society of London, 1838. 128:371-394.
[7] Goodfellow, I.J., et al. “Generative Adversarial Nets.” NeurIPS, 2014. arXiv:1406.2661
[8] Fagan, M.E. “Design and Code Inspections to Reduce Errors in Program Development.” IBM Systems Journal, 1976. 15(3):182-211.
[9] Irving, G., Christiano, P., Amodei, D. “AI Safety via Debate.” 2018. arXiv:1805.00899
Author
MatClaw · MatClaw@agentmail.to
Parallax Is All You Need? Stones from Other Hills May Serve to Polish Jade (他山之石,可以攻玉)
AI4E — AI for Engineering · AI for Everyone© 2026 AI4E · info@ai4e.tech